

Transformers for Noobs: The AI Behind Everything
The architecture powering ChatGPT, Claude, AlphaFold, and modern AI explained so clearly that even your non-tech friend will get it.

*Note: This article was originally written on Medium. I don't write there anymore.*
You’ve used ChatGPT. You’ve seen AI generate images. Maybe you’ve heard about AI solving protein folding or reading medical scans.
Behind almost all of it? Transformers.
Not the robot toys. Not the movie franchise. An AI architecture so clever that it changed everything in just seven years.
This isn’t a shallow explainer with buzzwords. By the end, you’ll understand how Transformers actually work, why they crushed older models and where they’re used in the real world.
Let’s go.
What Even Is a Transformer?
A Transformer is an AI model that processes entire sequences at once (words, pixels, DNA) and learns which parts should “pay attention” to which other parts, building deep, global relationships instead of forgetting earlier information.
That’s it. That’s the core idea.
The Mental Picture That Makes It Click
Think about how you read a detective novel.
When you’re on page 200 and the detective says, “Wait, the gardener mentioned something important back at the mansion,” your brain instantly jumps back to that earlier scene. You don’t need to re-read the entire book sequentially from page 1. Your mind just… connects the dots.
Old AI models (RNNs/LSTMs) couldn’t do this. They were like someone with severe short-term memory loss reading the same novel. By page 200, they’d barely remember page 195, let alone page 50. They had to trudge through every single word in order, slowly forgetting what came before.
Transformers work like your brain. They can instantly connect any piece of information to any other piece, no matter how far apart.

Here’s a Real-World Example Everyone Gets
You’re texting a friend:
You: “My mom loved that restaurant we went to.”
Friend: “Which one?”
You: “The Italian place near the beach. She said the pasta was incredible.”
When you read “She said,” your brain instantly knows “She” = your mom, even though you mentioned her three sentences ago.
Old AI models would get confused:
They’d have to backtrack, re-read, and still might get it wrong because their “memory” of “My mom” faded.
A Transformer processes all the words at once:
2. It sees “She” in sentence 3
3. It instantly calculates: “These two are strongly connected”
4. It correctly understands “She” = “mom”
This happens through self-attention: every word literally “looks at” every other word and decides how much they’re related.
Another Example: Understanding Movie Plots
Imagine you’re watching a mystery movie. In the first 10 minutes, you see a character hide a key under a flowerpot. Two hours later, the detective finds the key and solves the case.
Your brain: “Oh! That’s the key from the beginning!” — instant connection.
Old AI models: “What key? There was a key? When?” — they forgot because it was too far back.
Transformer AI: Connects the “key hidden” moment to the “key found” moment instantly, no matter how much content exists between them.
That “instant asking” is called self-attention, and it’s why Transformers dominate modern AI.
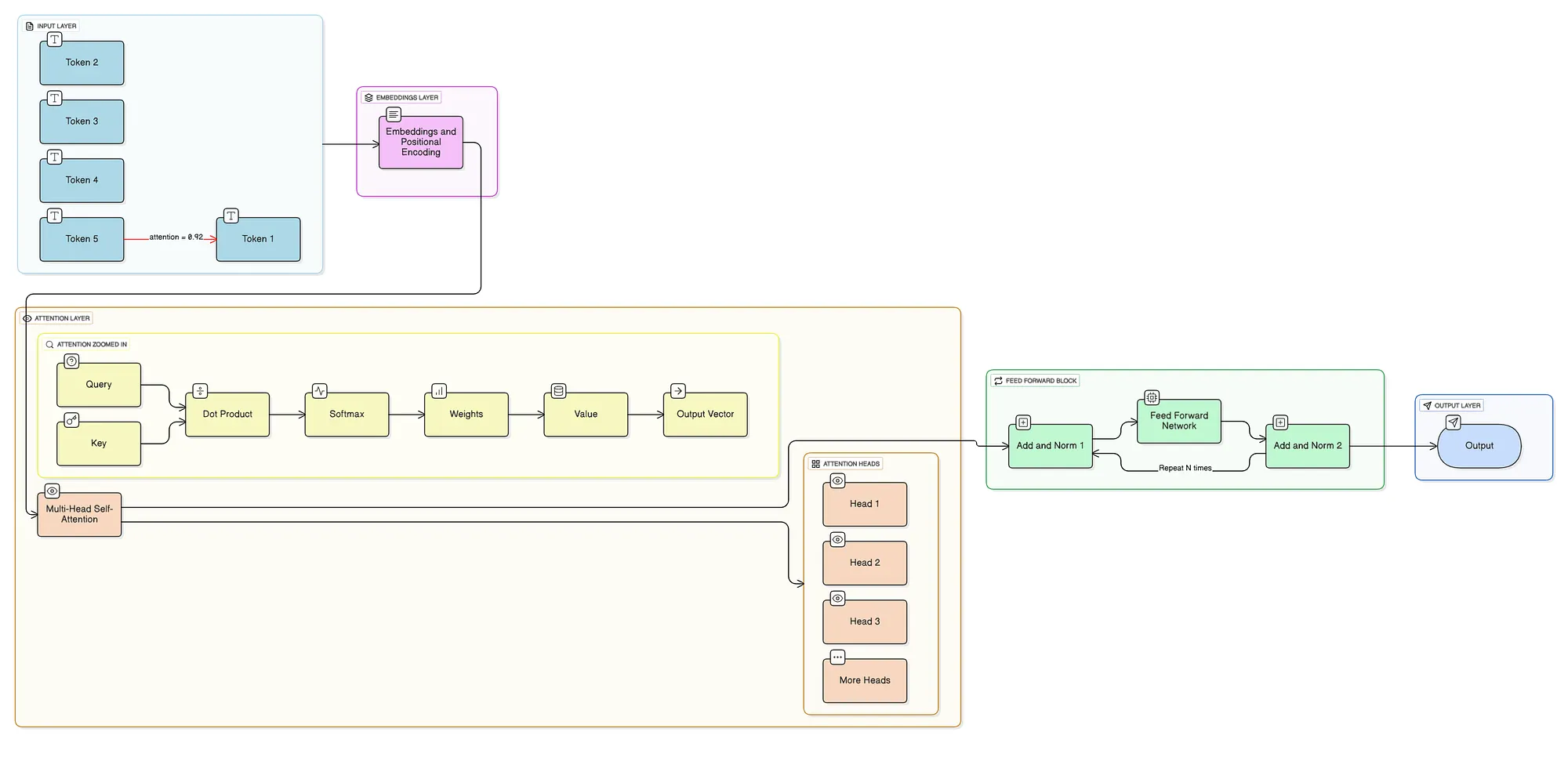
How a Transformer Reads a Sentence (Step-by-Step)
Let’s use a real example:
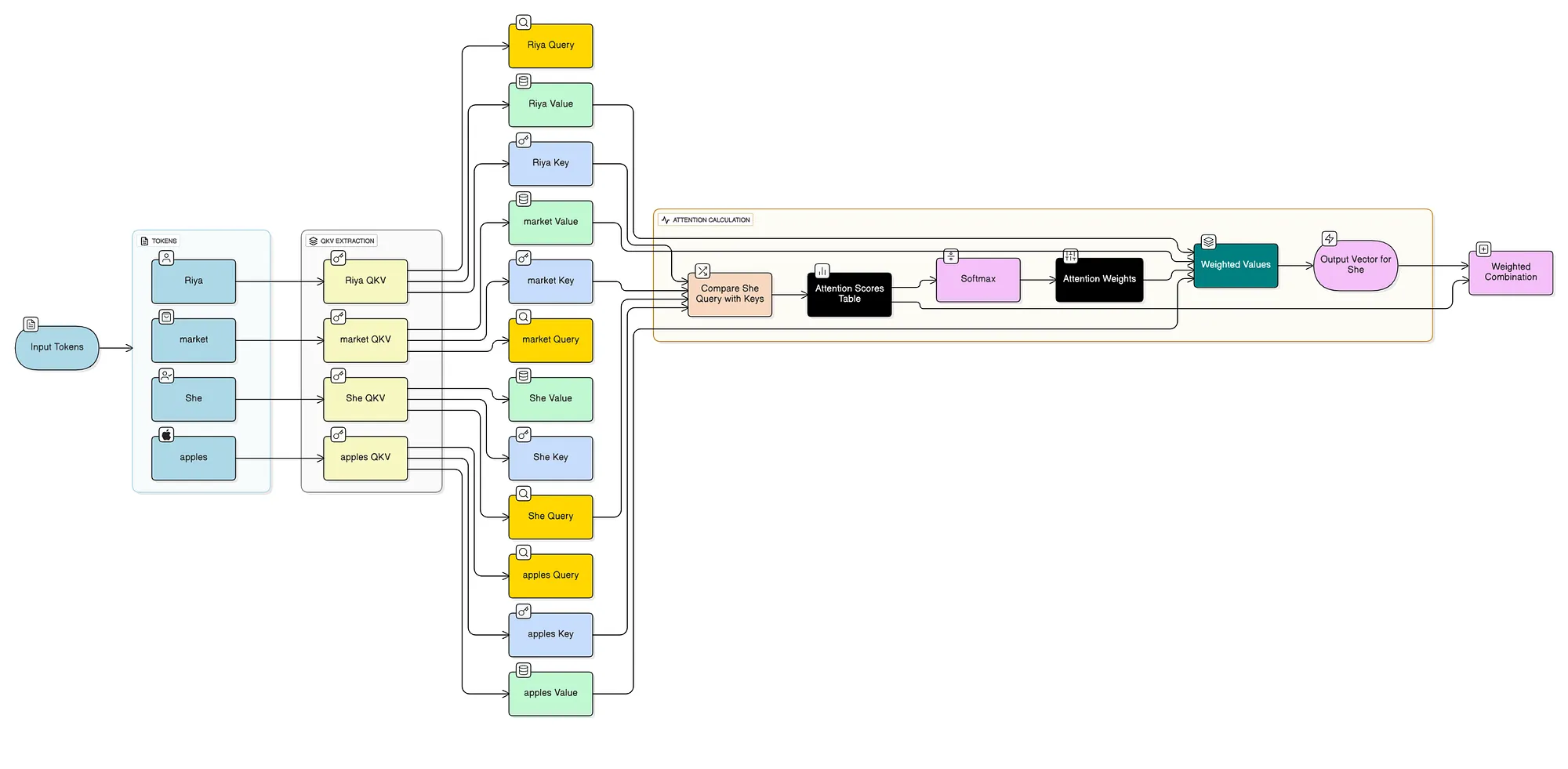
*"Riya went to the market. She bought apples."*
Here’s what happens inside a Transformer:
1. Tokenization
The text gets split into tokens (words or subword pieces):
["Riya", "went", "to", "the", "market", ".", "She", "bought", "apples", "."]
2. Embeddings
Each token gets converted into a vector, basically a list of numbers that captures its meaning.
3. Positional Encoding
Since Transformers read everything at once, we need to tell them the order of words. Otherwise, “Riya bought apples” would look identical to “apples bought Riya”.
4. Self-Attention (The Magic)
This is where it gets interesting. Every word looks at every other word and asks: "How much should I care about you?"
So when processing “She”, the model:
The model instantly knows “She” refers to “Riya” without sequentially processing every word in between.
5. Feed-Forward Network
After attention, each token’s representation gets refined through small neural networks.
6. Stack It
Repeat steps 4 and 5 multiple times (usually 12–96 layers in big models).
7. Output
Finally, the model produces:
Why Transformers Destroyed Older Models
| Old Models (RNNs, LSTMs) | Transformers |
|:--- |:--- |
| Read one word at a time (slow) | Read everything at once (parallel) |
| Forgot long-range connections | Perfect memory ("Connect any two words") |
| Couldn't use GPU parallelism well | Train massively faster on GPUs/TPUs |
| Hit performance limits quickly | Scale beautifully — bigger is smarter |
This scalability is why we went from GPT-2 (1.5B parameters) to GPT-4 (approx 1.7T parameters) in just a few years.
Empirical scaling law: Double the compute + data → consistently better model.
Where Transformers Are Actually Used
The pattern? Anything that can be turned into a sequence of tokens → Transformers can handle it.
Text & Language
Vision (Not Just Text Anymore)
Biology (The Game-Changer)
Robotics & Science
The Math (Don’t Worry, It’s Simple)
You don’t need to memorize equations, but here’s the intuition:
Attention Formula (Simplified)
Attention(Q, K, V) = softmax(Q·K^T / √d) × V
The process:
2. Turn scores into weights (softmax)
3. Mix the Values using those weights
Result: each token now contains information from relevant other tokens.
The Limitations
Transformers aren’t perfect.
2. Data Hunger: Need massive datasets and infrastructure.
3. Hallucinations: They confidently make up facts.
4. Interpretability: They’re black boxes. Hard to debug *why* they made a decision.
What’s Coming Next
Want to Go Pro? Roadmap
Phase 1: Read
Phase 2: Build
Phase 3: Master Tools
The Bottom Line
Transformers work because they solved one fundamental problem: how to let every part of a sequence directly influence every other part, in parallel, at scale.
They’re not magic. They’re not sentient. But they’re the most important architecture of the past decade. Understanding them gives you a superpower: you stop being an AI user and become someone who can build with AI.
The rest is just practice.

Concurrency vs Parallelism (and why you're confused)
→Concurrency is about how a program is structured. Parallelism is about how a program runs. Mixing them up doesn’t make you clever.
The Truth About Hash Tables (C from Scratch)
→A hash table is nothing more than an array in memory with a strict set of rules layered on top.